在线收集大规模异构任务和多技能参与者,可以实现任务和参与者的实时共享。然而,他们的在线聚会会带来许多棘手的客观要求,这使得任务参与者匹配变得极其复杂。为了更好地处理聚集,论文设计了一个层次树和时间序列队列来组织任务和参与者。论文设计的数据结构可以有效地满足任务和参与者在线聚会带来的所有需求。此外,基于所设计的数据结构,论文从计算模式、树生成方法和匹配策略的扩展三个方面研究了在线大规模异构任务分配问题。论文提出的最佳方法(TsPY)在计算模式上基于并行计算,在树生成方法中采用先时间后空间的方法,在匹配策略中增加了短距离优先策略。最后,论文在不同的参与者地理分布(即均匀分布、高斯分布和签入经验分布)、不同的感知方法(即参与式感知和机会主义感知)和不同的推荐方法(即点推荐和轨迹推荐)条件下进行了详细的实验。实验结果表明,TsPY在算法运行时间、任务参与者匹配率、参与者出行距离、冗余任务移除等多个指标上都有较好的性能。
该成果由韩磊(西北工业大学在读博士研究生)、於志文(西北工业大学教授)、於志勇(福州大学教授)、王亮(西北工业大学副教授)、尹厚淳(西北工业大学在读硕士研究生)、郭斌(西北工业大学教授)合作完成,“Online Organizing Large-scale Heterogeneous T asks and Multi-skilled Participants in Mobile Crowdsensing”发表在IEEE Transactions on Mobile Computing(CCF A类推荐期刊)
简介:
群智感知(MCS)是一种新的感知范式,它以大量普通用户的移动设备为基本感知单元,通过物联网和移动互联网进行协作,实现任务分配和数据采集,最终完成复杂的城市和社会感知任务。在线大规模异构任务分配是群智感知(MCS)任务分配中一类极其复杂但十分重要的问题。其复杂性在于,大规模异构任务和多技能参与者的在线聚集将带来丰富多样的客观需求。然而,他们在线聚会的优势是显而易见的。任务和参与者的不平衡分布可能会导致参与者招募和任务分配非常困难。在线收集可以克服这一困难,使任务和参与者实时共享,如图1所示。然而,如何构建一个任务分配平台,允许大规模异构任务和多技能参与者实时共享?为了回答这个问题,文章罗列了大规模异构任务和多技能参与者在线聚集所带来的所有需求,其包括丰富的技能类别、任务的非规则时空约束、多任务时空重叠、多技能参与者、任务和参与者实时到达或离开、兼顾参与式感知和机会式感知以及需要兼顾点推荐和轨迹推荐。
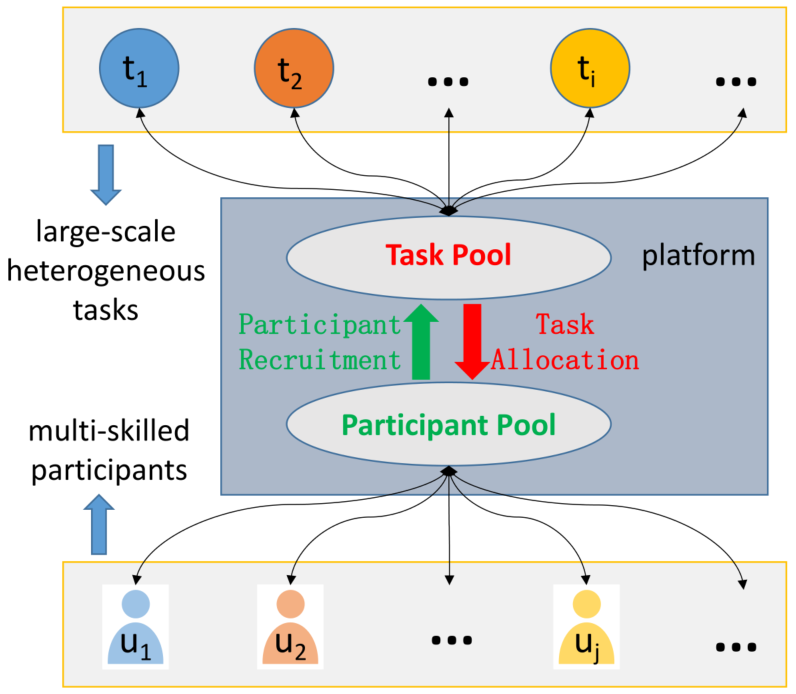
图1. 任务和参与者共享平台
针对在线大规模异构任务分配问题,尽管许多研究人员已经对在线大规模异构任务分配问题进行了详细的研究,但研究人员需要针对问题的部分方面设计特定的算法。然而,在线大规模异构任务分配平台需要同时满足上述所有要求。仅仅设计一种特殊的算法来满足部分需求是不适用的。为什么现有的任务参与者匹配算法只能满足部分需求?众所周知,数据结构是算法的基础。然而,现有匹配算法所依赖的数据结构(即队列和/或集合)过于简单。基于这些简单的数据结构设计算法以同时满足所有棘手的目标要求几乎是不可能的。为什么队列和集合很难应用?根本原因是队列和集合的索引效率极低且庞大,这将导致索引的时间复杂性太高,无法接受。相比之下,上述要求对指数的效率和灵活性提出了很高的要求。例如,丰富的技能类型和多技能参与者需要经常匹配技能;任务的不规则时空需求和多任务的时空重叠将导致任务去冗余和协同分配变得极其复杂;动态参与者和任务需要自由插入和删除。因此,要解决在线大规模异构任务分配问题,关键是设计灵活有效的数据结构来组织大规模异构任务和多技能参与者。在在线大规模异构任务分配平台中,合理的数据结构应该能够实时处理大规模异构任务和多技能参与者。即,数据结构必须能够满足大规模异构任务和多技能参与者在线聚集所带来的所有需求。
为了解决在线大规模异构任务分配问题,论文做了以下工作。首先,将时间和空间原子化。将空间和时间划分为任务时空约束的最小单元。单元的大小取决于平台处理任务的精度,即时空分辨率。然后,根据时空分辨率将大规模异构任务划分为原子化任务,并使用层次树对这些原子化任务进行组织。层次结构树包含四层,即技能层、时间层、空间层和原子化任务层(即叶节点)。基于层次结构树组织任务不需要提前列出所有技能。层次树的技能层可以自由扩展。同时,空间层和时间层也可以自适应,删除和插入任务可以是任意的。此外,层次树可以方便地实现并行计算,从而显著提高任务参与者匹配的效率。在组织参与者方面,设计了一个时间序列队列来组织动态参与者。将参与者的多个属性打包,例如空间约束、时间约束、技能约束等。根据参与者的时间限制将其更新到队列中。基于时间序列队列的参与者组织既可以是参与式感知,也可以是机会主义感知,还可以是点推荐和轨迹推荐。最后,论文复制并扩展了常用的任务参与者匹配算法,以评估我们设计的数据结构。
方法设计:
图2显示了在线大规模异构任务分配平台的框架。论文将平台分为四层:资源层、数据结构层、算法层和输出层。资源层聚集了大规模的异构任务和多技能参与者。数据结构层组织原子化的任务和打包的参与者,以便于索引。算法层根据索引数据结构匹配任务和参与者。输出层输出匹配结果并反馈任务执行状态。
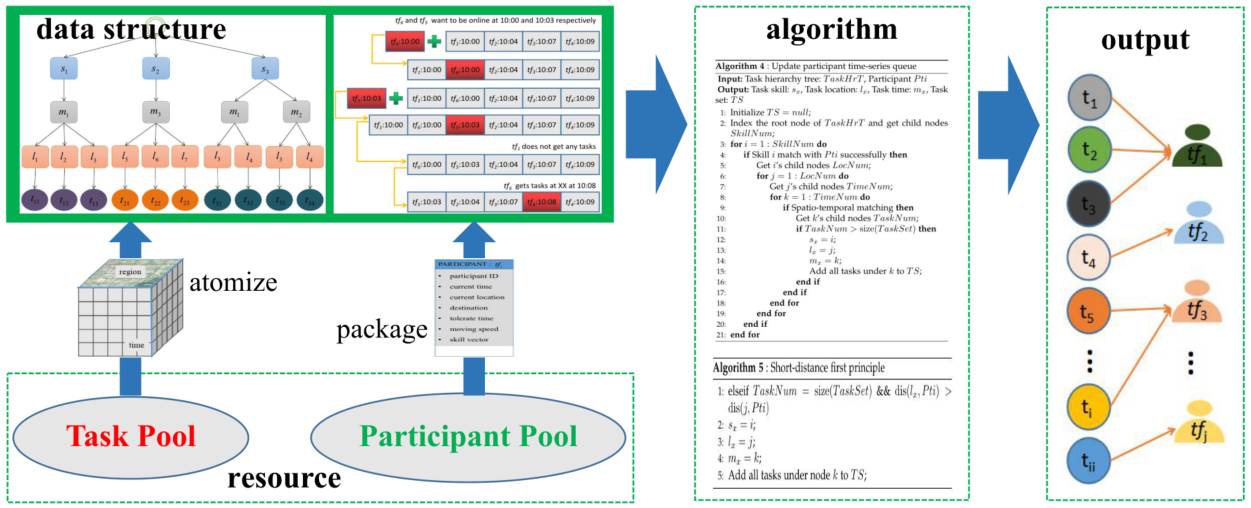
图2. 在线大规模异构任务分配平台框架
在资源层,当任务和参与者加入任务池和参与者池时,任务提供者首先丰富任务内容和技能类型。这是一个众包过程,参见百科全书创建过程。为什么任务提供者帮助平台丰富任务内容和技能类型?首先,技能类型控制具有特定技能的参与者的招募。平台无法招募技能类型中没有技能的参与者。更重要的是,如果技能不匹配,任务质量就无法保证。其次,任务内容控制任务冗余。删除冗余任务可以降低任务的执行成本。
在数据结构层,它主要包括四个部分:原子化任务、包参与者、更新层次树和时间序列队列。首先,根据技能、时间和空间三个属性,将原始任务划分为几个原子化任务。然后根据技能、时间和空间将原子化的任务插入到层次结构树中。同时,对参与者的所有属性进行打包,并根据参与者的时间属性将其更新到时间序列队列中。
在算法层,我们复制了常用的任务参与者匹配算法。此外,论文对原有的基于同一层次树和时间序列队列的任务参与者匹配算法进行了扩展,以展示其易于扩展性。注意到任务参与者匹配算法不是我们的研究重点,它只是评估设计的数据结构。
在输出层,有两种情况:成功执行任务和失败执行任务。当任务成功执行时,返回传感数据。当任务执行失败时,还有两种情况。首先,如果任务截止日期尚未到来,该任务将作为新任务重新添加到任务池中。第二,如果任务截止日期已到,任务将被删除并返回失败。
数据结构层和算法层是在线大规模异构任务分配平台的核心。且论文的研究重点在平台的数据结构层。因此,论文重点讨论任务原子化、构建任务层次树和参与者时间序列队列。
原始任务根据技能、时间和空间三个属性进行原子化。论文根据固定的大小离散时间和空间,如图3所示。其大小取决于平台处理任务的精度,这被称为时空分辨率。根据时空分辨率对原始任务进行划分,将不规则的原始任务转化为规则的原子化任务,以满足任务的不规则时空需求。此外,将原始任务转化为原子化任务后,复杂的时空重叠变得简单:完全重叠和完全不重叠。
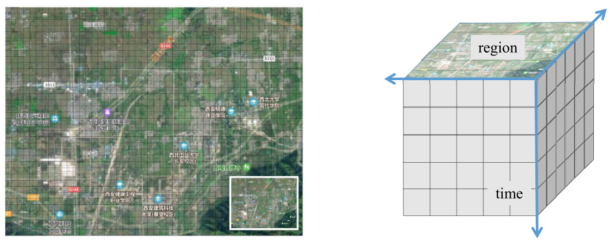
图3. 时空离散化
论文设计了一个层次树来组织原子化的任务。将任务层次树分为四层,即技能层、时间层、空间层和原子化任务层(即叶节点)。值得注意的是,技能是由需求驱动的。任务需要什么样的技能,平台需要招募具备这些技能的参与者。基于层次结构树组织任务不会提前列出所有技能类型。层次树的技能层可以自由扩展。同样,空间层和时间层也可以自由扩展。任务层次结构树可以动态删除或插入任务。任务层次树的生长过程如图4所示。
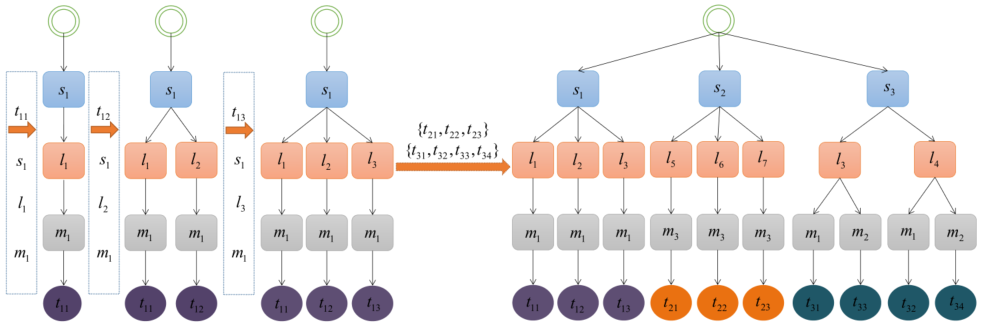
图4. 层次树的生长过程
创建任务层次结构树有两种方法:先空间后时间,或先时间后空间。将技能层设置在顶层有利于实现任务参与者匹配算法。准确匹配参与者技能和任务所需技能是匹配任务参与者的基础。然而,哪一个空间层和时间层在前面对创建任务层次树有很大影响。图5(a)和图5(b)分别是根据空间优先和时间优先生成的两个任务层次树。
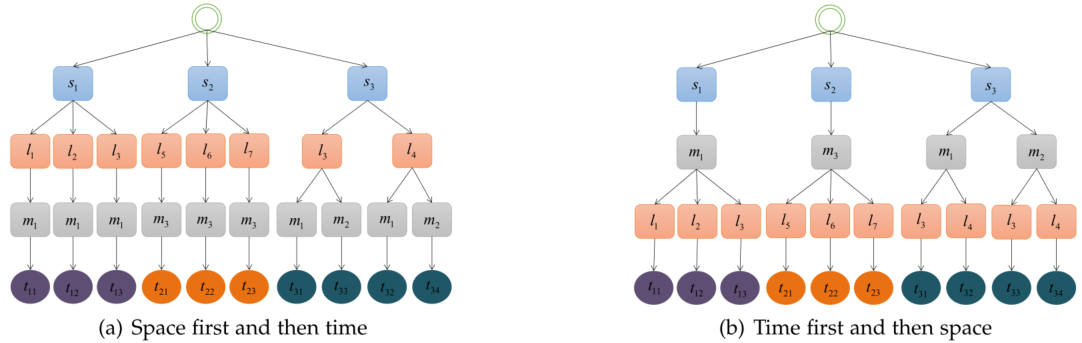
图5. 层次树的创建方法
任务参与者匹配有两种计算模式:串行计算和并行计算。这些任务是参与者的共享资源。任务参与者匹配是互斥的,不能将一个任务分配给多个参与者。换句话说,只能允许一个参与者在一个时刻遍历任务层次结构树(即串行计算)。这种计算模式对于任务参与者匹配非常低效。然而,在线平台对及时性的要求很高。如何提高任务分配的效率非常重要。如今,大多数计算机的处理器都是多核的,这意味着计算机可以实现真正的并行计算。因此,如果允许多个参与者同时遍历任务层次树,就可以充分利用计算机的并行计算能力,大大提高任务参与者匹配的效率。如何在不违反任务-参与者匹配互斥的前提下充分利用计算机的并行计算能力?任务层次结构树有一个巨大的优势,其可以根据多个参与者的技能将任务层次树划分为多个子树。然后,多个参与者可以同时遍历不同的子树来实现并行计算。任务层次树的划分如图6所示。
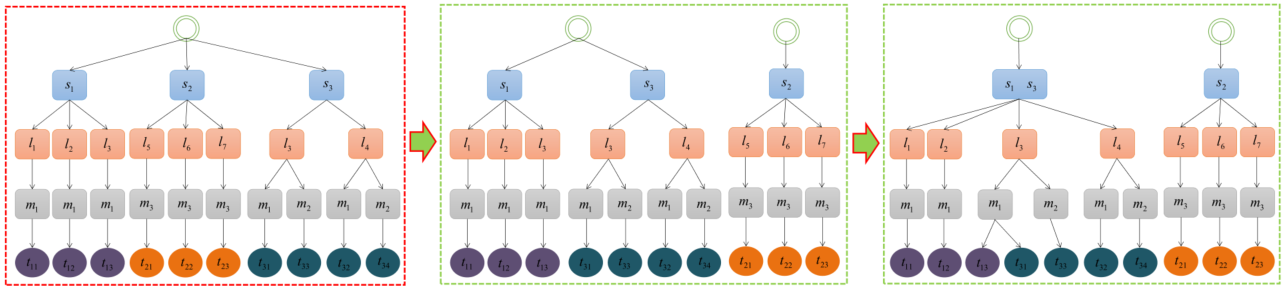
图6. 任务层次结构树的分解和合并示例
论文设计了一个时间序列队列来组织参与者。参与者有七个属性:参与者ID、当前时间、当前位置、目的地、到达目的地的容许时间、移动速度和技能向量。特别提示:移动速度仅用于计算参与者的旅行时间。在真实环境中,第三方地图API可以准确估计行程时间。将这七个属性打包,并根据参与者的当前时间将参与者更新到时序队列中。参与者时间序列队列更新算法如图7所示。这里有两点需要注意。(1)当参与者的目的地和到达目的地的可容忍时间为空时,这意味着参与者是参与性的。如果参与者有明确的目的地和到达目的地的时间,这意味着参与者是机会主义的。(2)通过索引时间序列队列来控制推荐方法。如果平台总是保持时间序列队列为空,这就是轨迹推荐。如果平台只为当前时间为系统时间的参与者编制索引,那么这就是点推荐。

图7. 时序队列更新过程
论文进行了详尽的实验评估,代表性实验结果如表1和表2所示。与串行计算相比,并行计算可以大大减少算法的运行时间。算法运行时间平均可减少66.00%以上。与空间优先相比,基于时间优先的任务层次树的创建可以大大提高任务参与者的匹配率。匹配率最低可提高6.00%以上,最高可提高20.00%以上。延长短距离优先原则可以减少参与者的出行距离。旅行距离最低时可减少3.00%以上,最高时可减少5.00%以上。任务内容的重复率越高,删除的冗余任务就越多。对于不同的推荐方法、不同的感知方法和不同的地理分布,并行计算可以大大减少算法的运行时间。时间优先、空间优先可以显著提高任务-参与者匹配率,延长短距离优先原则可以减少参与者的出行距离。
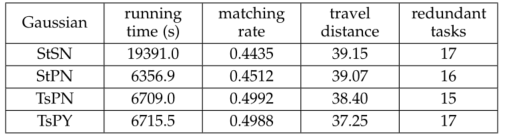
表1. 高斯分布假设下的实验结果
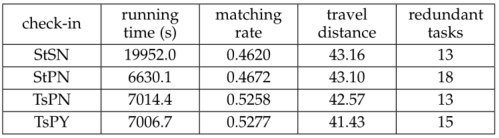
表2. 模拟签到数据分布下的实验结果
总结:
在线收集和共享大规模异构任务和多技能参与者具有巨大优势。它可以有效地缓解由于地域分布不均而造成的任务和参与者匹配困难。然而,他们的在线聚会将带来许多棘手的客观要求。论文总结了七项要求,如丰富的技能类别、任务的非规则时空约束、多任务时空重叠、多技能参与者、任务和参与者实时到达或离开、兼顾参与式感知和机会式感知以及需要兼顾点推荐和轨迹推荐。为了同时满足所有需求,论文设计了一个层次树和一个时间序列队列来组织任务和参与者。基于所设计的数据结构,论文从计算模式、树生成方法和匹配策略的扩展三个方面研究了任务分配问题。在计算模式方面,比较了串行计算和并行计算。在树的创建方法方面,比较了空间优先和时间优先。在匹配策略的扩展方面,论文扩展了短距离优先原则。最后,论文对算法运行时间、任务参与者匹配率、参与者出行距离和冗余任务移除四个指标进行了详细的实验评估。实验结果表明,基于层次树和时序队列的任务参与者匹配算法能够有效地满足上述要求。与串行计算相比,在实验环境下,并行计算平均可以减少66%以上的算法运行时间。与先空间后时间相比,基于先时间后空间创建树可以平均提高任务参与者匹配率13%以上。延长短途优先策略可以将参与者的出行距离平均减少4%以上。




